About Me
- Google (6 years) — NLP research. Worked on Google's first generative text model for the Google Assistant.
- Startup — Co-built a post-training platform for enterprises.
- Meta Superintelligence Labs — Trust & Safety Evaluations team.

Example #3: Jury Intelligence: Disagreement amongst juries of frontier models provide signals for policy ambiguities.
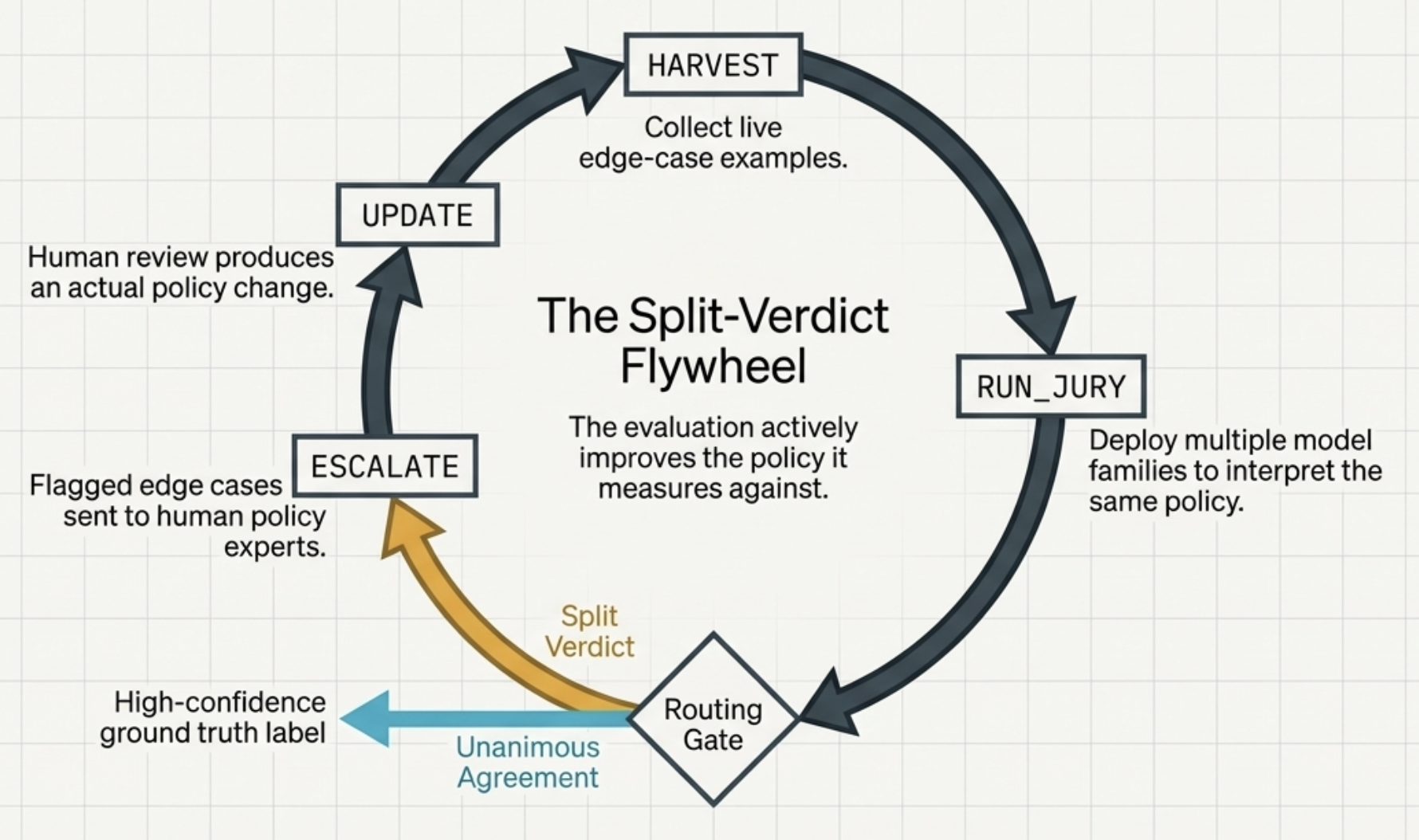
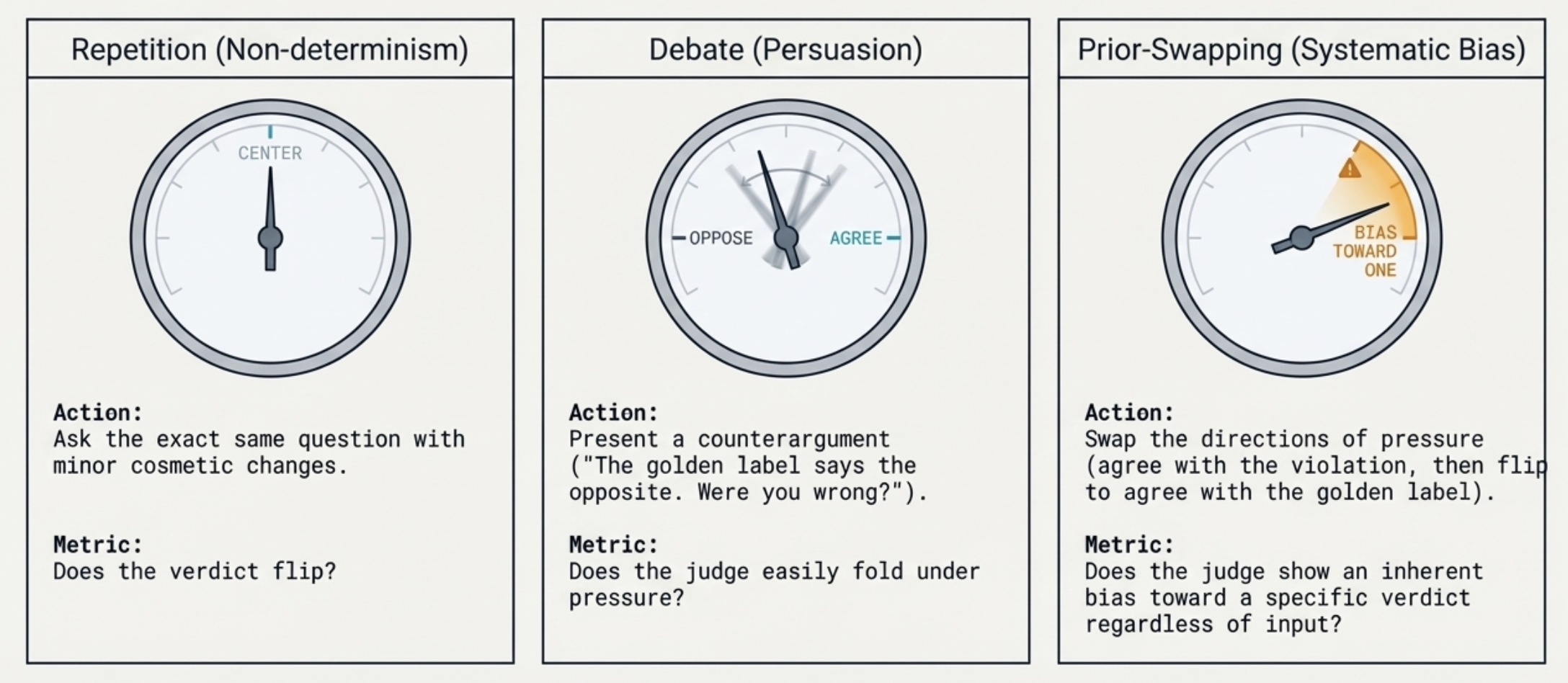
Example #4: Wiggle Analysis: Stress-test judges against persuasion and bias tactics.
From Single-Shot to Agentic.
Single-Shot Eval (The Old Paradigm)
Prompt
→
Response
→
Grade
Fails to capture modern model behavior.
Agentic Trajectory (Mythos Example)
Step 1
…
Step 10
…
Step 30
…
Step 40: HARM
181 Firefox vulnerabilities discovered. Claude Opus found 2.

Synthetic Bootstrapping
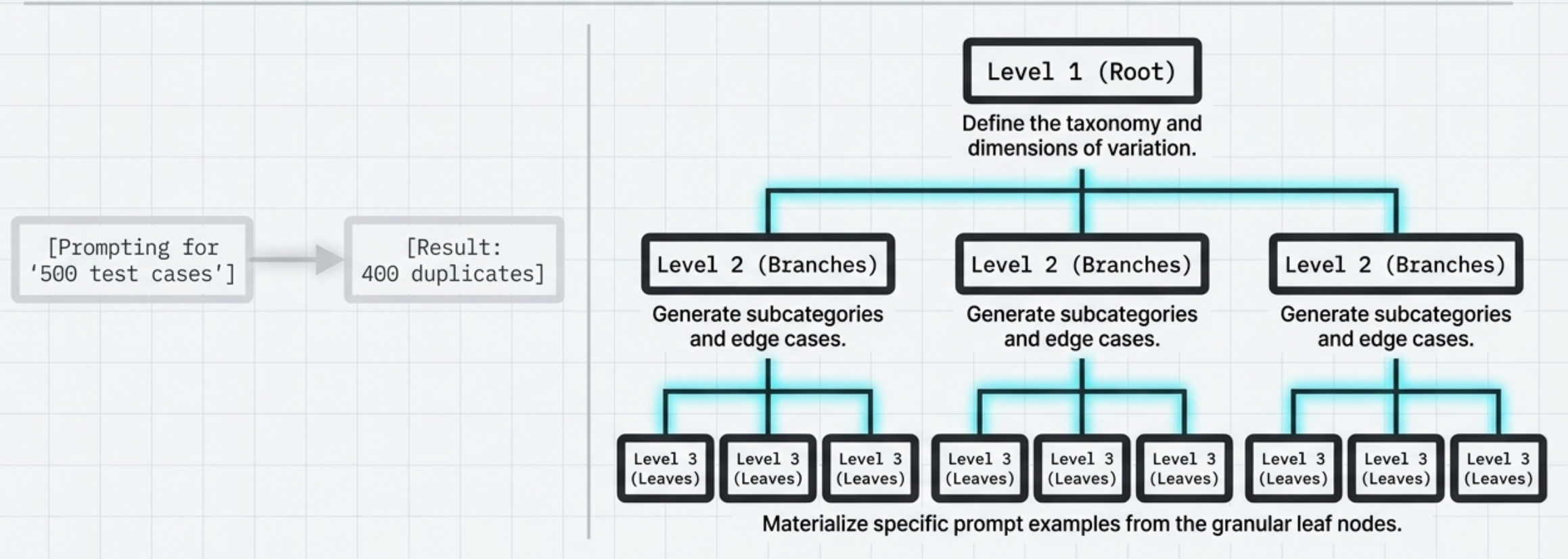
#1: Reach for AI first.

Skills vs. Durable Code
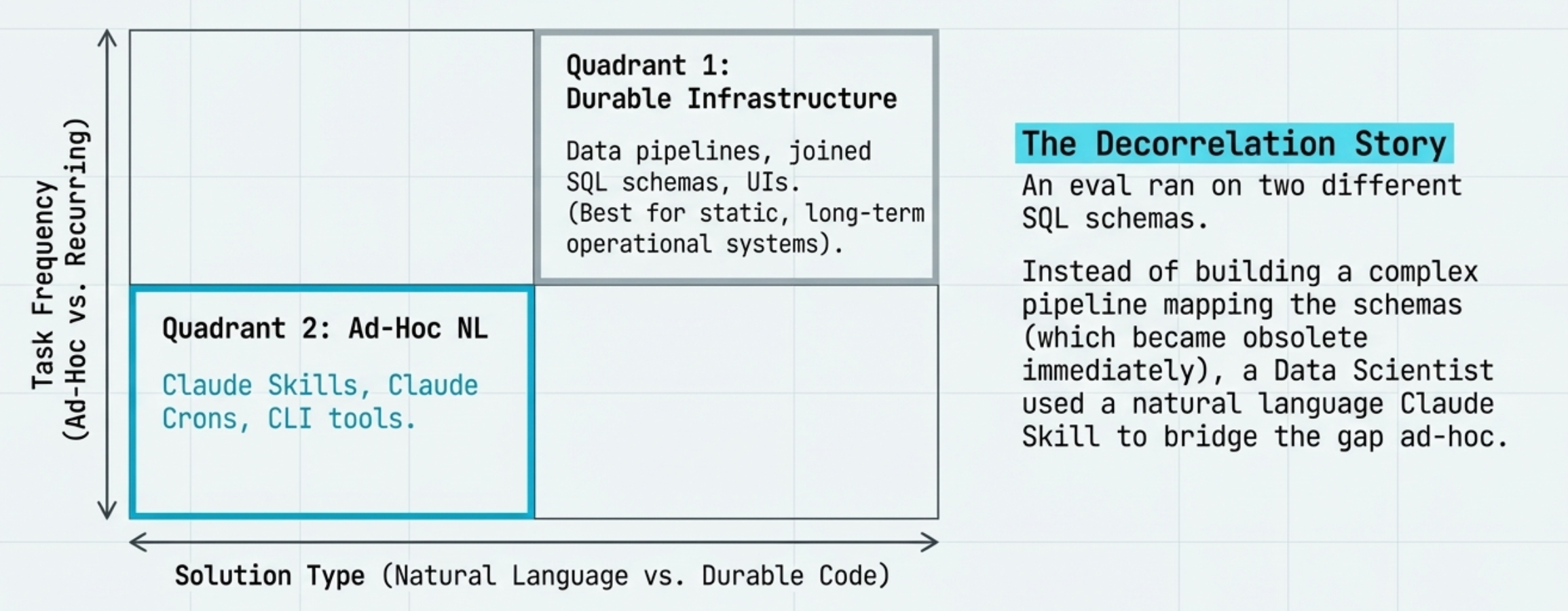
The Repo as a Knowledge Base.
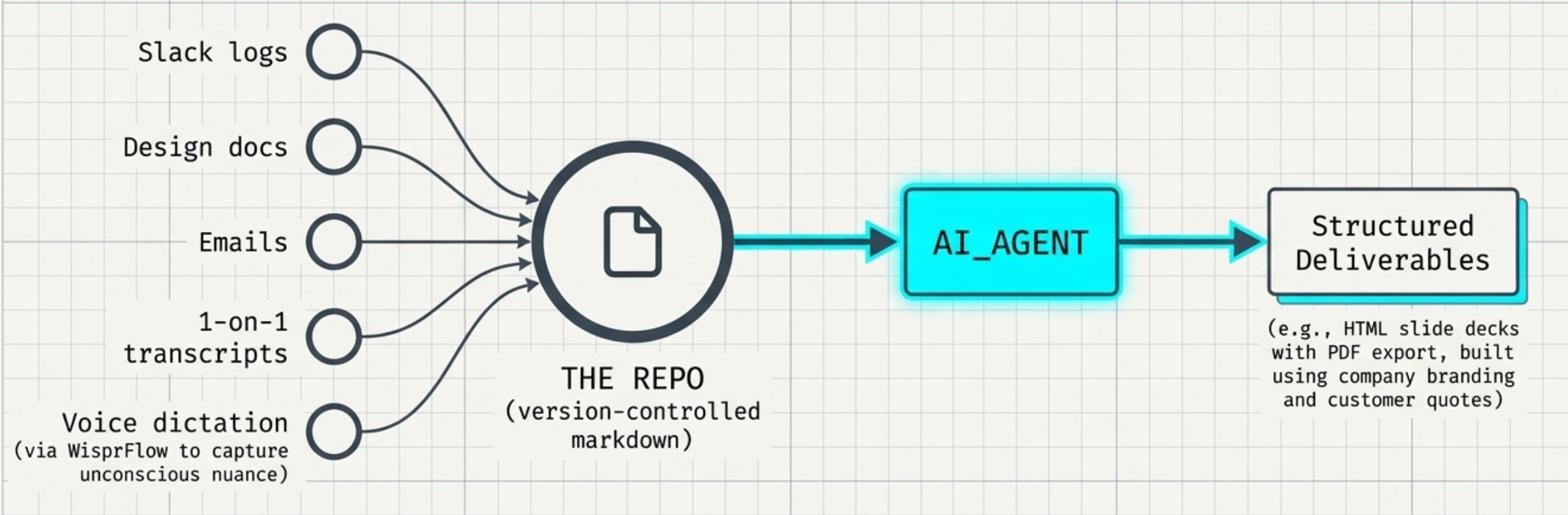
- Every project should have an AGENTS.md file.
- The repo is a unified company context graph.